GUI Agent
关于纯视觉通用GUI Agent的一些思考
大模型的发展历程中,有三个重要的里程碑,它们分别是:
2017年 - 谷歌团队在论文《Attention is All You Need》中首次提出了注意力机制(Attention Mechanism)和Transformer架构,这一创新极大地推动了自然语言处理(NLP)领域的进步。
2020年,Scaling Law,由OpenAI的研究团队在论文《Scaling Laws for Neural Language Models》中正式提出。这篇论文由首次系统地探讨了Decoder-only模型的性能与模型大小、数据集大小和训练计算量之间的关系。研究发现,当模型的计算量、参数量和数据量中的任何一个因素受限时,模型的性能与该因素之间存在幂律关系。通过增加模型的参数量和训练数据量,可以显著提升模型的性能,尤其是在达到一定规模后,模型会展现出“涌现”现象,即一些小规模模型无法实现的能力会在大规模模型中突然出现。
Chain of Thought (CoT) - 随着深度学习模型的进一步发展,研究者发现大型预训练模型能够通过一种称为“思维链”的方法来进行更为复杂的推理任务。这种方法通过逐步思考的方式模仿人类的决策过程,从而提升了模型解决复杂问题的能力[3]。经典例子是在给大模型的提示词中添加一句“lets think step by step”。
ReAct介绍
#2023年的ReAct,是在CoT上的进一步发展。CoT是一种静态的过程,模型利用现有知识一次将所有流程推理完,但由于幻觉的存在,以及现实世界中每一段流程行动的结果的不可预料性,往往会导致任务失败。因此ReAct提出将推理和行动结合起来,交替地生成推理和动作,从而更好地协同工作。根据实验结果,该方法比纯CoT在HotpotQA(一个需要在两段或更多维基百科文章之间进行推理的多跳问题回答基准)和Fever数据集上有约3%的准确率提升。
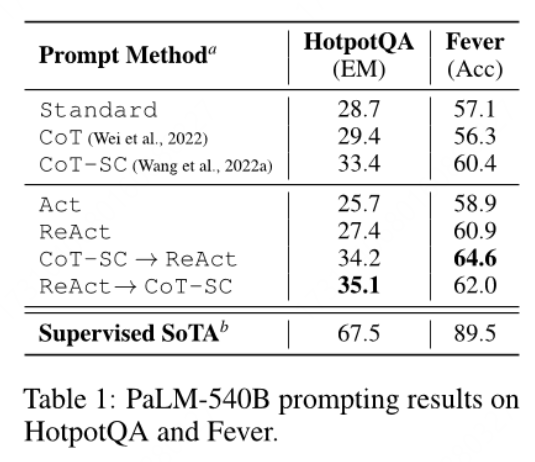
虽然准确率提升不高,但是ReAct的优势在于,当模型成功给出答案时,其错误率比CoT低得多(6% vs. 14%)。ReAct的主要劣势在于,当某一步推理出现错误导致操作错误时,模型无法判断该如何进行下一步以修正前一步的错误操作,导致模型不停尝试跳出错误场景。经过微调后,模型熟悉该数据集下的操作,ReAct的准确率会提升,而CoT的准确率反而降低。因为CoT的微调本质上是教模型记住(潜在地幻觉化)知识事实,ReAct教模型如何推理并行动以访问来自维基百科的信息,这是一种更通用的知识推理技能。这也彰显了ReAct的发展潜力。
Agent介绍
Agent,代理,也称为智能体,指能够感知环境并采取行动的实体。历史上,由基于智能系统的强化学习主导了这一领域,在其中,代理通常被分配执行简单的、定义明确的动作或任务,并且与环境进行约束下的交互。然而,这种方法在适应性和复杂性方面存在固有局限性,促使人们探索更高级和互动性的基于代理的系统。大型语言模型 (LLM) 在推理和规划方面表现出非凡的潜力,与人类对基于 LLM 的代理感知其周围环境、做出决策并采取行动的能力期望高度一致。受此启发,基于 LLM 的代理在与复杂环境交互以及解决广泛应用程序中的各种任务方面取得了显著进展。诸如各类辅助进行代码编写的智能体,辅助进行信息查询的智能体。但值得注意的是,当前有相当多的所谓Agent充其量只是一个bot(如聊天机器人)。
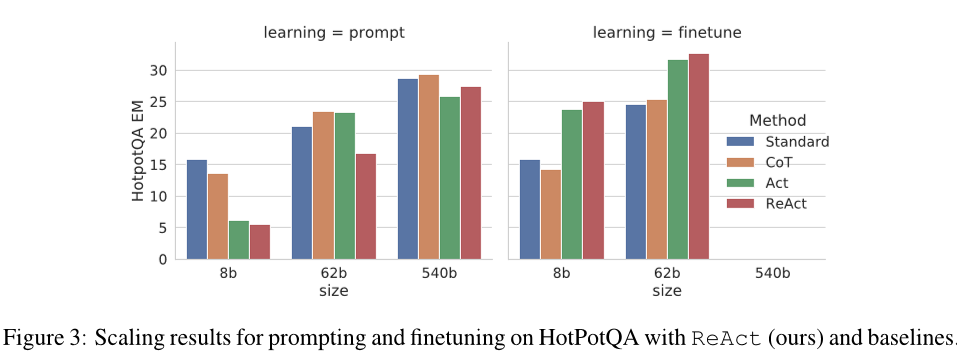
随着大语言模型的发展,有许多工作探索了使用大视觉语言模型作为基座的GUI Agent,代替人类完成繁琐的任务。一种工作线是训练一个端到端模型直接预测下一个动作,代表性的作品包括:对网页操作的Pixel2Act 、WebGUM,对移动端设备操作的Ferret 、CogAgent 和Fuyu;另一种工作线涉及利用现有的多模态模型如GPT-4V来执行用户任务。代表性的有在网页端的作品MindAct、SeeAct ,以及一些移动端的作品。这些工作通常利用浏览器中的DOM信息或移动应用程序中的视图层次结构来获取屏幕中可交互元素的真实位置,并使用Set-Of-Marks 来叠加边界框,然后将截屏上的边界框输入到视觉语言模型中。然而,当目标是构建一个适用于跨平台和跨应用程序任务的通用智能体时,屏幕上的交互元素可能存在巨大差别。因此,即使是当前最先进的方法也与一个通用型的GUI Agent存在着显著差距.
总之,当前研究指出,大型多模态模型已经表现出对UI截图中包含的元素具有理解能力,但将大模型预测的动作转换为对屏幕的实际动作(键盘/鼠标的移动以及API的调用)仍有困难,关键挑战之一便是动作定位,现有的大模型无法输出准确的xy坐标。现有的最先进方法为Set-Of-Marks,该方法提出在原始图像上叠加一组带有唯一数字ID的边界框作为视觉提示发送给模型。从而令模型能够将动作定位到具有真实位置的特定边界框中而不是特定xy坐标值,这大大提高了动作定位的鲁棒性,然而,SoM方法依赖于解析HTML信息来生成可交互元素的边界框,这将任务局限在了web端。
Omniparse
为了解决上述挑战,研究人员提出了一种通用的屏幕解析工具Omniparse,用来替代SoM,用于将用户界面截图解析为结构化元素,以增强GPT-4V在多个操作系统和不同应用程序中作为通用代理的能力。该方法通过使用流行的网页和图标描述数据集来训练专门化的模型:一个检测模型来解析屏幕上的可交互区域,以及一个标题模型来提取检测到元素的功能语义。实验结果表明,OMNIPARSER显著提高了GPT-4V在ScreenSpot基准测试中的性能,并且在Mind2Web和AITW基准测试中,仅使用截图输入时,OMNIPARSER比需要额外信息的GPT-4V基线表现更好。
首先可以看到,相比于只添加边界框的SoM方法,为每个边界框添加了语义(框内元素的解释信息)的方法准确率有大幅提升。实验的数据集来源为作者手工制作的一个包含112个任务的数据集SeeAssign。

ScreenSpot数据集是一个基准数据集,其中包括来自移动(iOS、Android)、桌面(macOS、Windows)和网络平台的超过600个界面截图。模型根据任务说明点击UI截图上的元素,测试指标为点击准确率。
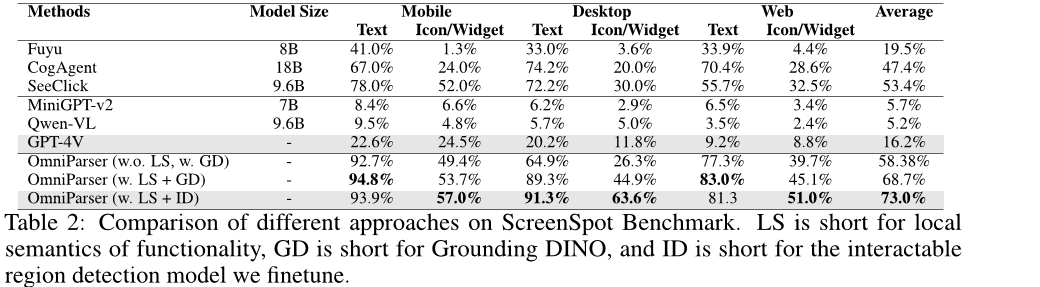
其中,LS为语义信息,GD为一个高性能目标检测模型,ID为作者团队微调的交互区域检测模型。
可以看到,Omniparser方法可以大幅提升模型操作的准确率,甚至大幅领先了在GUI数据集上微调的SeeClick、CogAgent和Fuyu。这些结果证明了GPT-4V对UI屏幕的理解能力被严重低估,并且可以通过更准确地检测可交互元素以及功能局部语义的整合而大大增强
具体来说,Omniparse的设计思路如下:
环境信息的精确采集:Omniparse系统通过收集屏幕截图的数据集,训练一个布局模型来识别屏幕上的可操作区域和不可操作区域,并为每个区域分配唯一的编号。这一过程确保了大模型能够获得准确的环境信息,从而做出更加合理的决策。
图像识别与功能标注:除了识别屏幕元素的位置,Omniparse还使用图像识别模型来为每个图标添加语义信息。这些信息与位置数据一起输入给大模型,使其能够根据当前任务的需求选择合适的操作区域。
决策与执行的闭环:在大模型做出决策后,Omniparse会将选定区域的精确坐标发送给执行工具,后者负责实际的点击操作。这一闭环设计确保了从决策到执行的每一个步骤都能精确无误地完成。
鲁棒性与适应性:Omniparse通过提供详细的环境信息,增强了Agent在面对复杂界面或非标准环境时的鲁棒性和适应性。例如,当Agent需要在一个充满广告和弹窗的网页上执行任务时,Omniparse能够帮助其准确识别目标元素,避免误操作。
这些工作的意义是什么呢?我认为有以下几点:
1.这是一个通用型的智能助手,可以在不同的系统环境下运行,不依赖系统本身的功能,也无需进行复杂的适配。
2.当面对封闭的软件或页面时可以运行。目前许多系统级的智能助手,比如各家手机厂商的手机上搭载的智能助手(华为的小艺,荣耀的yoyo等),运行时依赖操作系统提供的api,以及软件的api,当遇到不向系统开放底层api时,或是现有的api没办法满足用户的要求时,这些智能助手就无能为力。而本文提到的通用型的agent可以模仿人类进行点击,完成各类复杂的操作。
缺点:
1.运行效率低,资源消耗大。模型每一步操作之后都要上传截图重新进行推理,这一步会消耗大量token,模型推理也会消耗算力资源和时间,若模型部署在云端,通信也会消耗相当多的时间和资源。
2.智能体运行时人类无法操作机器。由于该流程中智能体是在模仿人类对机器进行操作,所以智能体运行时,需要对屏幕内容截图,操作鼠标键盘等工具,而人类对机器的操作同样需要操作这些工具,因此人的加入会打断智能体的工作,导致任务失败。
3.当前阶段智能水平还不高,容易被干扰,处于几乎不可用的阶段。当前阶段,任务成功率仍然不足80%,且弹窗等意外事件在机器使用过程中会经常发生,当前水平的大模型对这些意外事件的鲁棒性非常差,遇到弹窗时任务成功率不足20%。
4.缺少商业落地场景。对于企业来说,最大的收入来自于ToB业务,而B端的任务往往具有高度定制化的特点,通用型智能助手效果往往不佳,且B端对准确率和效率的要求比C端用户高得多,这正是当前智能体的不足之处。而对于C端用户来说,目前仍缺乏对这样一个智能体的使用场景,用户也缺乏消费意愿。